Tokens
A seção Tokens do relatório oferece uma análise detalhada do número de tokens processados por pergunta (Requisições da API) para cada modelo da sua conta.
Os tokens processados representam as unidades de texto efetivamente utilizadas em cada interação, considerando tanto o tamanho da pergunta enviada pelo usuário quanto o tamanho da resposta gerada pelo modelo.
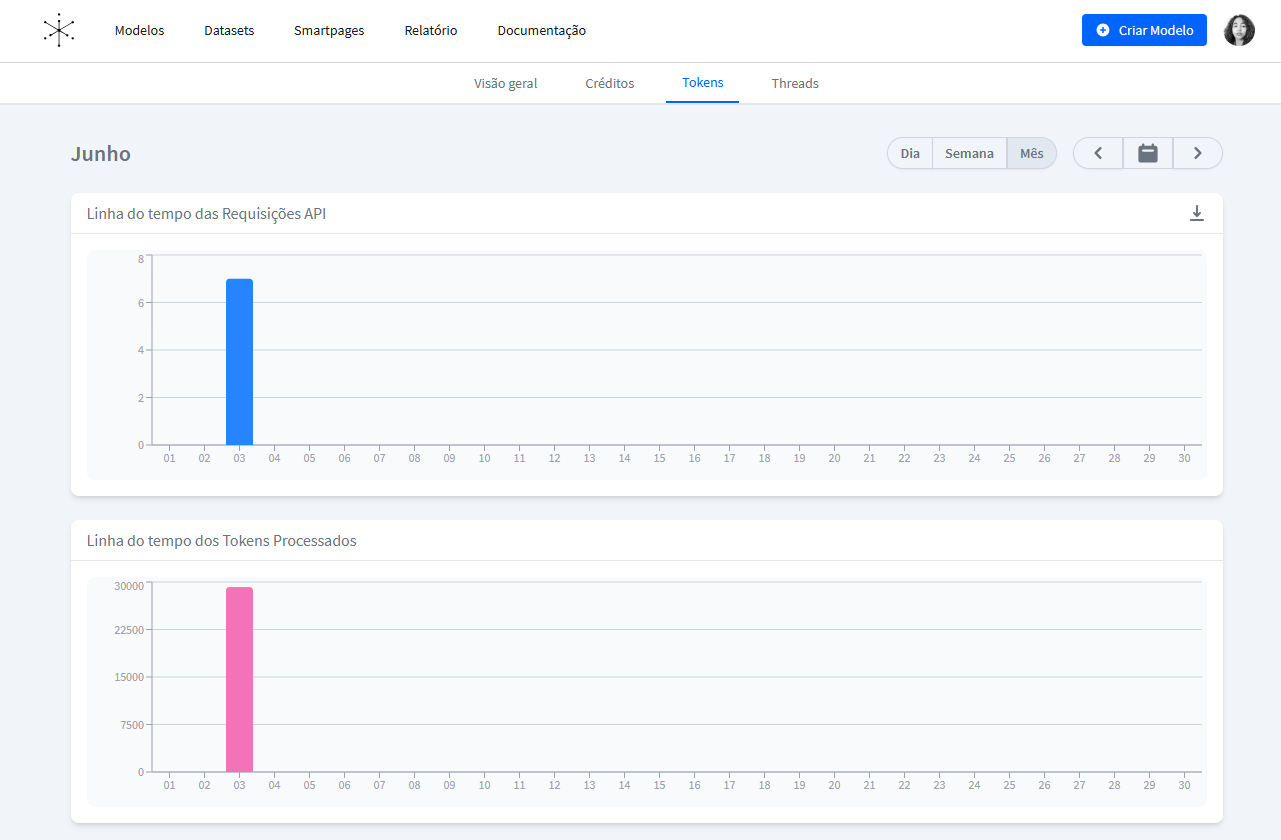
Os filtros oferecem uma visão personalizada para analisar determinados períodos, além disso, há possibilidade de exportar estes dados para uma análise interna, considerando os Principais Modelos por Uso de Tokens:
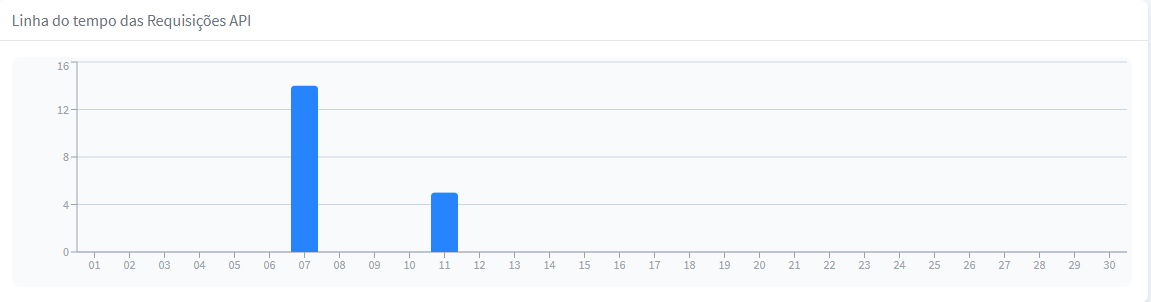
Linha do tempo das Requisições API
A linha do tempo das Requisições API apresenta visualmente o total de requisições de API com base no período selecionado, facilitando a análise de padrões e tendências.
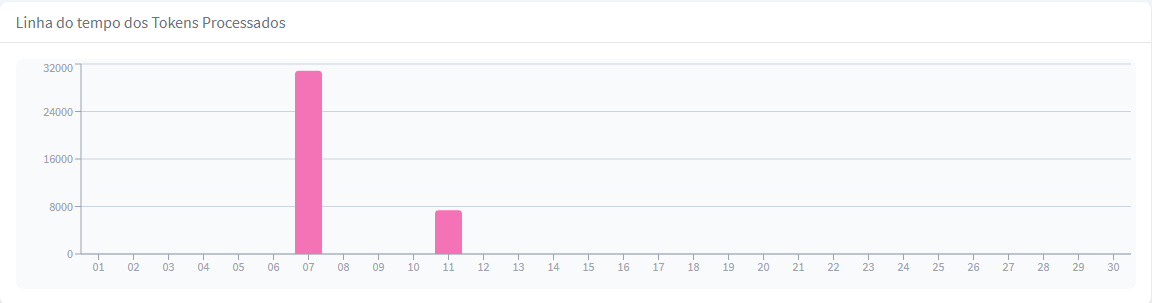
Linha do tempo dos Tokens Processados
Já a Linha do tempo dos Tokens Processados exibe o total de tokens processados com base no período selecionado, facilitando a análise de padrões e tendências.
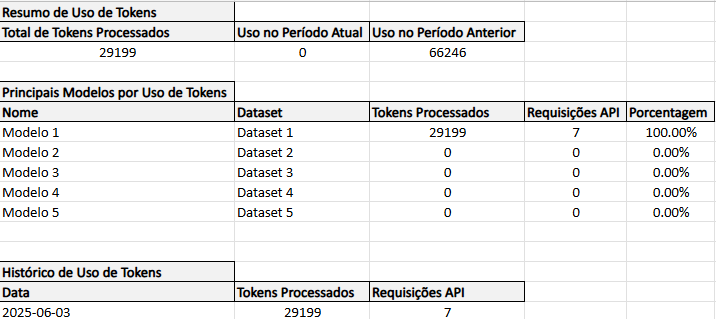
Principais Modelos
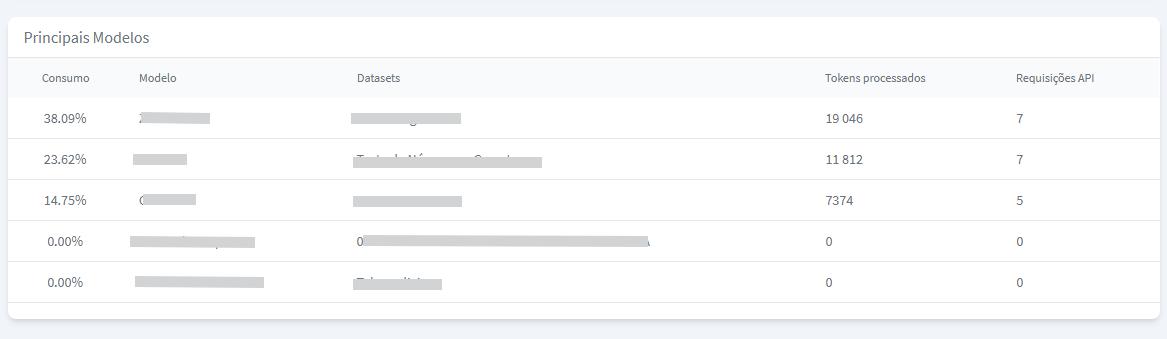
A seção Principais Modelos do relatório oferece uma visão detalhada e organizada dos modelos mais utilizados na sua conta, com base no consumo de tokens processados.
Essa tabela permite que você identifique quais modelos estão demandando mais recursos e como eles estão sendo utilizados. As colunas apresentadas são:
Consumo: Mostra o percentual de tokens processados que cada modelo consumiu em relação ao total da sua conta. Essa métrica ajuda a identificar quais modelos têm maior impacto no uso de recursos.
Modelo: Exibe o nome do modelo, facilitando a identificação e organização dos diferentes modelos em uso.
Dataset: Indica o conjunto de dados (dataset) atrelado ao modelo, ou seja, a base de conhecimento que ele utiliza para gerar respostas.
Tokens Processados: Apresenta a quantidade total de tokens processados pelo modelo, considerando tanto as perguntas enviadas pelos usuários quanto as respostas geradas
Requisições de API: Mostra o número total de requisições feitas para o modelo, indicando a frequência de uso.
Updated 9 months ago